아스키코드
문자 인코딩(character encoding)은 문자 집합을 메모리에 저장하거나 통신하는 데 사용하기 위해 부호화하는 방식을 말한다. 대표적인 예로 모스 부호를 들 수 있다.
문자 집합(character set)은 문자를 모아 둔 것이다. 예를 들면 라틴문자가 있다. 주목할 점은 다양한 언어(영어, 프랑스어, 독일어)가 라틴문자를 사용한다는 점이다.
0과 1밖에 모르는 컴퓨터에 문자를 인식시키려면 문자를 0과 1로 이루어진 2진수로 나타내야 한다. 문자 하나에 정수 하나를 매핑해 두면 이 정수는 특정 문자를 표현하게 된다. 이렇게 매핑된 정수를 코드 포인트라고 하고, 문자와 문자에 매핑된 코드 포인트를 모아 놓은 집합을 문자 집합(Coded Character Set, CCS)이라고 한다.
아스키(American Standard Code for Information Interchange)는 대표적인 문자 인코딩 방식이다. 비트 일곱 개로 문자를 표현하므로 문자를 총 128개까지 표현할 수 있다. 당연히 코드 포인트 수도 128개다.
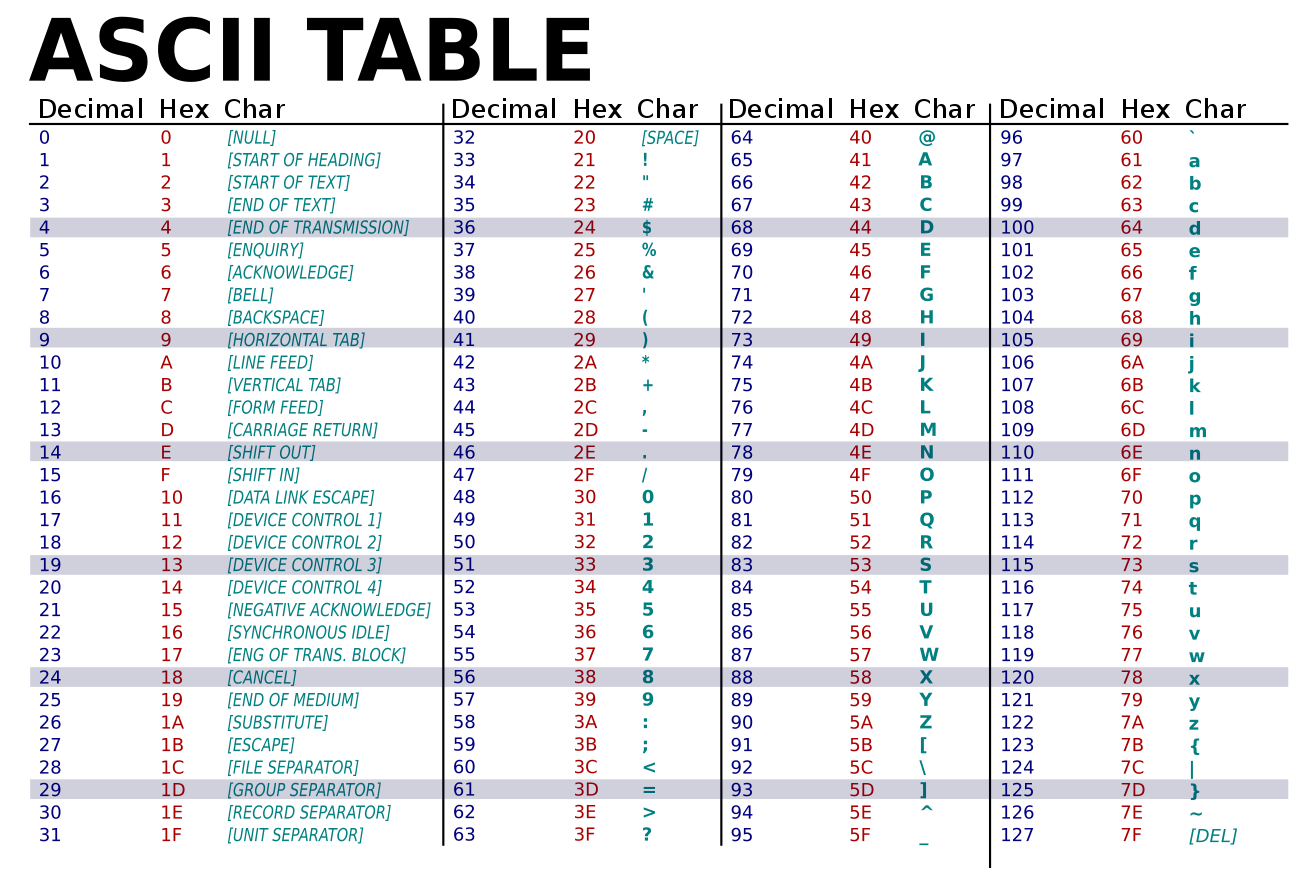
예를 들어 대문자 A는 10진수로는 65, 16진수로는 0x41이다. 소문자 a는 10진수로는 97, 16진수로는 0x61이다. 숫자 문자인 0은 10진수로는 48, 16진수로는 0x30이다.
>>> ch = 'A'
>>> bch = ch.encode()
>>> bch
b'A'
>>> bch[0]
65
>>>
>>> ch_0 = '0'
>>> bch_0 = ch_0.encode()
>>> bch_0
b'0'
>>> bch_0[0]
48A와 65, 0과 45가 매핑되었음을 알 수 있다.
아스키코드를 보면 정수 0부터 127까지 문자와 매핑되어 있다. 2진수로 0000 0000(0)부터 0111 1111(127)까지이므로 표현하는 데 최대 7비트가 필요하다. 정수를 나타내는 데 쓰는 자료형은 바이트 수에 따라 다양한데, int형이 가장 많이 쓰인다. int형은 32비트 컴퓨터에서 일반적으로 4바이트(32비트)다. 이보다 작은 short형은 2바이트(16비트)다. 아스키코드를 표현하는 데는 7 비트면 층 분하므로 int형이나 short형을 쓰면 메모리가 낭비된다. 그래서 문자를 표현하기 위해 char형이라는 새로운 정수 자료형을 만들었다. char형은 문자를 담기 위해 만들어진 자료형이지만 정수 자료형이므로 작은 수를 표현하는 데 사용하기도 한다.
유니코드
전 세계적으로 컴퓨터가 보급되고 인터넷을 통해 세계 각국의 사람들이 커뮤니케이션을 하면서 컴퓨터에서 쓸 수 있는 언어가 더 필요해졌다. 이때 나온 해결 방법이 7비트로 표현한 문자를 16비트로 확장하는 것이다. 7비트일 때는 128개의 문자를 표현할 수 있지만 16비트로 확장하면 65,536개의 문자를 표현할 수 있다. 여기에 더해 수 하나에 다시 문자 하나를 일대일로 대응한 새로운 표를 만들었는데. 이 테이블이 유니코드다.
>>> '\uAC00'
'가'
>>> '\uAC01'
'각'코드 유닛(code unit)은 코드 포인트를 특정한 방법으로 인코딩했을 때 변환되어 얻어지는 비트의 나열을 말한다.
문자 인코딩 방식(Character Encoding Scheme)은 코드 유닛을 옥텟으로 나열하여 변환하는 방법이다. 옥텟(octet)은 데이터의 단위로 8비트를 의미한다. 지금은 1바이트를 당연히 8 비트라고 생각하지만, 예전에는 1바이트가 반드시 8비트가 아니었으므로 옥텟이라는 용어를 따로 사용했다. 현재 컴퓨터는 모두 8비트 단위를 사용하므로 코드 유닛을 옥텟으로 변환해도 실제로 비트가 바뀌지는 않는다.
유니코드는 2바이트로 숫자 하나에 문자 하나를 대응하여 문자를 표현한다. 기본 다국어 평면을 포함해 평면이 열일곱 개 있으므로 모든 문자를 표현하려면 3바이트가 필요하다. 언뜻 생각하면 코드 유닛의 크기를 3바이트로 하고 코드 포인트를 그대로 저장하면 될 것 같지만 쉽게 결정할 문제가 아니다.
만약 1바이트 정수만 저장할 수 있는 시스템이라면 3바이트짜리 정수는 저장할 수 없으므로 이 시스템에서는 한글을 표현할 수 없다. 그러므로 다양한 코드 유닛을 갖는 인코딩 방식을 두어 유연하게 대처해야 한다.
파이썬 문자열의 특징
C/C++에서는 문자열을 변수로 만들면 요소인 문자를 변경할 수 있고, 문자열을 상수로 만들면 요소를 변경할 수 없다. 즉, 프로그래머가 변경 가능성을 선택할 수 있다.
하지만 파이썬의 문자열은 요소를 변경할 수 없다. 변경을 시도하는 순간 오류가 발생한다.
>>> string = 'abcde'
>>> string[2]
'c'
>>> string[2] = 'a'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object does not support item assignment문자열 string에서 가운데 위치한 c를 x로 변경하고 싶다면, string의 요소를 직접 변경하지 않고 문자열 슬라이싱을 사용해 요소를 변경할 수 있다.
>>> new_string = string[:2] + 'x' + string[3:]
>>> new_string
'abxde'
다른 방법은 내장 함수(Built-in function) 중 하나인 replace() 함수를 사용하여 변경하는 방법이다. replace() 함수 인자에 기존 문자열과 바꿀 문자열을 전달하면 바뀐 문자열을 반환한다. 하지만 이번에도 string의 요소를 직접 변경하지 않았다는 점을 주의하자.
>>> string = 'abcde'
>>> new_string = string.replace('c' , 'x')
>>> new_string
'abxde'
>>> string
'abcde''Computer Science' 카테고리의 다른 글
| 컴퓨터의 동작 원리 (0) | 2021.10.28 |
|---|---|
| 컴파일러 언어vs 인터프리터 언어 (0) | 2021.05.09 |
| Home server (0) | 2021.04.10 |
| 실수 (0) | 2021.03.03 |
| 양의 정수와 음의 정수 (0) | 2021.03.03 |