-
자료구조 핵심 원리 - 그래프Algorithm 2022. 9. 24. 03:29
그래프는 로봇이 최단 경로를 계산해서 움직일 때나 내비게이션에서 경로를 안내할 때, 지하철역을 어디에 건설해야 가장 효율적인지 계산하는 등 매우 폭넓게 사용됩니다. 게다가 최근에 가장 중요한 이슈인 머신 러닝도 그래프를 활용합니다. 이 장에서는 그래프에 대한 이론적인 내용과 실제로 구현할 때 표현(representation), 모든 정점을 방문하는 방법인 순회(traversal) 등 그래프의 기본 내용을 다루어 보겠습니다.
1.1 그래프 용어 정리
자료구조 - 그래프
정의 그래프(graph)는 연결된 객체들 사이의 관계를 표현할 수 있는 자료구조이다. 지하철 노선도나 전기회로 같이 다양한 객체들이 서로 복잡하게 연결되어 있는 구조를 표현할 수 있는 논리적
edwardmoon.tistory.com

self-edge (자기 간선) self-edge는 정점 0이 tail이자 동시에 head인 경우를 말합니다. 일반적으로 그래프는 self-edge를 갖지 못합니다.

multi-grapth (멀티 그래프) 그래프에서는 일반적으로 에지 중복을 인정하지 않습니다. 중복 에지를 인정하는 자료 구조를 멀티그래프(multi-graph)라고 합니다.
1.2 그래프를 표현하는 두 가지 방법 : 인접 리스트, 인접 행렬
도시가 다섯 개 있고, 도시 사이에는 도로가 있는 경우도 있고 없는 경우도 있다고 하겠습니다. 이때 이 관계를 그래프로 어떻게 표현해야 할까요? 먼저 도시를 0부터 시작해서 4까지 숫자를 매깁니다. 도시와 도시 사이에 도로가 있다면 이 두 정점 사이에 에지가 있는 것입니다. 그래프를 인접 리스트(adjacency list)와 인접 행렬(adjacency matrix)로 표현해보겠습니다.

인접 리스트 위 그림의 인접리스트는 배열 한 개와 연결 리스트들로 구성되어 있습니다. 정점이 배열의 인덱스가 됩니다. 배열 요소인 연결 리스트는 해당 정점의 인접한 정점의 집합입니다.
정점 0을 보면 인접한 정점들이 {1, 3}이지요. 리스트 요소를 보면 1과 3이 있습니다. 정점 3을 볼까요? 정점 3에 있는 연결 리스트 요소는 {0, 1, 2}입니다. 이는 정점 3에 인접한 정점 집합임을 알 수 있습니다. 이렇게 구현할 때, 두 가지 연산의 빅오를 생각해 봅시다.
먼저 어떤 정점 v에 대해 인접한 모든 노드를 탐색하는 연산을 보죠. 해당 정점을 인덱스로 삼아 배열에서 연결 리스트를 얻어 온 후 이 연결 리스트를 순회하면 됩니다. 이 경우 모든 정점을 조사할 필요 없이 해당 정점의 인접한 정점들만 조사하게 되는군요. 그러므로 빅오는 O(d(v))입니다. 두 번째로 정점 u에 대해 (u, v) ∈ E(G)인지를 검사하는 연산입니다. 이때도 해당 정점을 인덱스로 연결 리스트를 가져와 인접한 모든 노드를 순회해야 하므로 빅오는 O(d(v))입니다

위 그림은 인접 행렬입니다. 각각의 행을 정점으로 보고 열을 자신을 포함한 다른 정점이라고 생각하면 (1행, 2열)은 정점 1과 정점 2 사이의 관계를 나타냅니다. 그림을 보면 해당 값이 0입니다. 이 값은 정점 1과 정점 2는 서로 인접하지 않다는 것을 의미합니다.
이차원 배열을 adj_matrix라고 합시다. 에지 (0, 1)이 있다면 adj_matrix[0][1]이 1이고 없다면 0입니다. 배열을 보면 adj_matrix[0][1]이 1이므로 에지 (0, 1)이 있습니다. 또 다른 특징은 무방향 그래프입니다. 그러므로 (0, 1)과 (1, 0)이 행렬에서 모두 1입니다. 즉, 이 행렬은 대각선에 대해 대칭입니다.
인접 행렬은 어떤 빅오를 가지는지 보겠습니다. 먼저 정점 v에 대해 인접한 모든 노드를 탐색하는 연산입니다. 이 경우 v행에 대해 모든 열을 검사해야만 합니다. 즉, 열 개수는 정점 개수이지요. 정점 개수를 n이라고 했을 때 O(n)입니다. 두 번째 연산인 (u, v)가 있는지 여부를 확인하는 연산은 어떤가요? adj_matrix[u][v]를 확인만 하면 되므로 O(1)입니다.
인접 리스트를 구현해 보겠습니다.
# graph_representaion.py class Graph: def __init__(self, vertex_num=None): # 인접 리스트 self.adj_list=[] self.vtx_num=0 # 정점이 존재하면 True # 정점이 없다면 False self.vtx_arr=[] # 정점의 개수를 매개변수로 넘기면 # 초기화를 진행합니다. if vertex_num: self.vtx_num=vertex_num self.vtx_arr=[True for _ in range(self.vtx_num)] # 배열의 요소로 연결 리스트 대신 동적 배열을 사용합니다. self.adj_list=[[] for _ in range(self.vtx_num)] def is_empty(self): if self.vtx_num==0: return True return False def add_vertex(self): for i in range(len(self.vtx_arr)): # 중간에 삭제된 정점이 있을 경우 # 이를 재사용합니다. # vtx_arr의 값이 False이면 # 삭제된 정점이라는 의미입니다. if self.vtx_arr[i]==False: self.vtx_num+=1 self.vtx_arr[i]=True return i # 삭제된 정점이 없다면 정점을 하나 추가합니다. self.adj_list.append([]) self.vtx_num+=1 self.vtx_arr.append(True) return self.vtx_num-1 def delete_vertex(self, v): if v >= self.vtx_num: raise Exception(f"There is no vertex of {v}") # 만약 정점 v가 존재하면 if self.vtx_arr[v]: # 정점 v의 인접 정점 집합을 초기화 self.adj_list[v]=[] self.vtx_num-=1 self.vtx_arr[v]=False # 나머지 정점 중 v와 인접한 정점이 있다면 # 그 정점의 리스트에서 v를 제거해줍니다. for adj in self.adj_list: for vertex in adj: if vertex==v: adj.remove(vertex) def add_edge(self, u, v): self.adj_list[u].append(v) self.adj_list[v].append(u) def delete_edge(self, u, v): self.adj_list[u].remove(v) self.adj_list[v].remove(u) def adj(self, v): return self.adj_list[v] # 그래프를 편하게 보기 위한 편의 함수 def show_graph(g): print(f"num of vertices : {g.vtx_num}") print("vertices : {", end="") for i in range(len(g.vtx_arr)): if g.vtx_arr[i]: print(f"{i}, ", end="") print("}") for i in range(len(g.vtx_arr)): if g.vtx_arr[i]: print(f"[{i}] : {{", end="") for j in g.adj_list[i]: print(f"{j}, ", end=" ") print("}")그래프 객체를 만들 때 매개변수로 정점 개수를 받도록 합니다. adj_list는 인접 리스트입니다. vtx_num은 정점 개수를 나타내고, vtx_arr은 정점의 존재 여부를 저장합니다. vtx_arr이 필요한 이유는 delete_vertex() 메서드로 도중에 있던 정점이 사라질 수 있기 때문입니다. 정점을 삭제할 때마다 뒤에 있는 모든 정점을 한 칸씩 당긴다면 인접 리스트의 모든 요소를 순회하면서 당겨진 정점을 모두 변경해 주어야 합니다. 이는 효율적이지 못하지요. delete_vertex() 메서드를 호출할 때 단순히 그 정점 인덱스를 비활성화한다면 훨씬 편합니다.
1.3 그래프의 모든 노드 방문 : 모든 도시를 여행해 보자
그래프는 선형 자료 구조가 아니기 때문에 모든 노드를 한 번만 방문하는 순회(traversal)를 구현하기가 쉽지 않습니다. 그래프의 모든 노드를 순회하는 방법은 두 가지입니다. 너비 우선 탐색(Breadth First Search, BFS)과 깊이 우선 탐색(Depth First Search, DFS)입니다. 너비 우선 탐색은 큐를 이용해서 구현하고, 깊이 우선 탐색은 스택을 기반으로 합니다. 이 둘은 많은 알고리즘에서 기본적으로 사용하고 있기 때문에 매우 중요합니다.
1.3.1 너비 우선 탐색(BFS) : 인근 도시부터 여행하기
아래의 그림은 너비 우선 탐색의 순서를 나타내고 있습니다. L1은 layer1입니다. 출발 정점 v가 3일 때 너비 우선 탐색은 먼저 정점 3을 방문한 후(L1) 정점 3에 인접한 모든 정점이 이루는 L2의 정점을 모두 방문합니다. 다음은 L2의 정점에서 인접한 정점들이 이루는 L3의 모든 정점을 방문합니다. 모든 정점을 방문할 때까지 계속 반복합니다.

BFS는 queue를 사용합니다.
# graph_traversal.py from queue import Queue class Graph: def __init__(self, vertex_num): # 인접 리스트로 구현 self.adj_list = [[] for _ in range(vertex_num)] # 방문 여부 체크 self.visited = [False for _ in range(vertex_num)] def add_edge(self, u, v): self.adj_list[u].append(v) self.adj_list[v].append(u) def init_visited(self): for i in range(len(self.visited)): self.visited[i] = Falsequeue 모듈에서 Queue 클래스를 가져옵니다. 파이썬이 제공하는 큐에는 enqueue 연산을 하는 put() 메서드와 dequeue 연산을 하는 get() 메서드가 있습니다.
이번 그래프는 단순하게 생성자에서 정점을 만들고 add_edge() 메서드에서 에지를 추가합니다. 생성자를 보면 visited라는 멤버를 확인할 수 있는데 BFS와 DFS 모두에서 정점의 방문 여부를 확인할 수 있는 매우 중요한 배열입니다. 각 정점을 방문했다면 True를 반환하고, 아직 방문하지 않았다면 False를 반환합니다. init_visited() 메서드는 visited 멤버의 모든 요소를 False로 만듭니다.
# graph_traversal.py def bfs(self, v): q=Queue() # 방문 체크 리스트를 초기화한다 self.init_visited() # 첫번째 정점을 큐에 넣고 # 방문 체크 q.put(v) self.visited[v]=True while not q.empty(): v=q.get() # 방문 print(v, end=" ") #인접 리스트를 얻어온다 adj_v=self.adj_list[v] for u in adj_v: if not self.visited[u]: q.put(u) self.visited[u]=True큐를 하나 만든 후 매개변수로 전달된 시작 정점을 먼저 삽입하고 큐가 비기 전까지 while 문을 실행하면서 모든 정점을 방문합니다. 원래 방문 목적은 해당 정점에서 어떤 연산을 수행하기 위해서입니다만, 이번 예제 목적은 어떻게 방문하는지 아는 것이므로 단순하게 정점을 출력하는 것을 방문으로 대신하겠습니다. while 문 내의 print(v, end=" ") 문이 방문입니다.






 0123456
0123456위 코드 bfs() 함수의 진행 순서 1.3.2 깊이 우선 탐색(DFS) : 한 방향으로 쭉 따라 여행하기
깊이 우선 탐색(DFS)은 스택을 사용합니다. 재귀 함수로 호출하는 형태인데, 함수 실행 중 다른 함수를 호출하면 스택 프레임이 쌓입니다. 먼저 스택 프레임을 이용하여 묵시적으로 스택을 사용하는 경우와 스택 자료 구조를 명시적으로 사용하는 경우를 모두 살펴보겠습니다. 먼저 재귀 함수를 사용해서 구현하는 코드를 보겠습니다.
# graph_traversal.py def __dfs_recursion(self, v): #방문 print(v, end = " ") #방문 체크 self.visited[v] = True adj_v = self.adj_list[v] for u in adj_v: if not self.visited[u]: self.__dfs_recursion(u) def dfs(self, v): self.init_visited() self.__dfs_recursion(v)코드에서 __dfs_recursion()과 dfs()를 보고 혼란스러울 수 있지만 dfs에서 __dfs_recursion을 호출하기 전에 visited 배열을 초기화하고자 dfs를 만든 것뿐입니다. 중요한 메서드는 __dfs_recursion입니다. __dfs_recursion을 보면 매개변수로 v를 받습니다. 그 후 먼저 방문을 하고 visited[v]를 True로 만들지요. 그러고 나서 adj[v]를 구합니다. adj[v]를 순회하며 방문하지 않은 정점을 방문할 때는 그 정점을 인수로 전달하며 __dfs_recursion을 호출합니다.

BFS는 시작 정점을 기준으로 인접한 모든 노드를 차례로 방문하며 마치 퍼져 나가듯이 방문했습니다. 하지만 DFS는 이와 다르게 시작 정점에서 한 방향을 정하고 그 분기로 쭉 따라간 후 더 이상 갈 곳이 없어지면 다시 시작 정점으로 돌아와 가보지 않은 방향으로 쭉 따라가는 특성이 있습니다. 그래서 이름도 깊이 우선 탐색입니다. 그림을 보면 시작 정점 3에서 시작하여 정점 0 쪽으로 쭉 따라간 후 정점 1에서 더 이상 갈 곳이 없어지면 다시 시작 정점으로 돌아옵니다. 그다음 다시 정점 4 방향으로 쭉 따라 이동하면서 방문한 후 다시 정점 3으로 돌아와 더 이상 갈 곳이 없어지면 종료됩니다. 여기서 중요한 점은 반드시 시작 정점으로 돌아온 후 더 이상 갈 곳이 없어야만 실행이 종료됩니다.

위의 그림을 보면 시작 정점이 2입니다. 맨 처음 __dfs_recursion(2)를 호출하겠지요. 그림에서는 간략히 dfs_rec로 표기했습니다. 메서드 내부를 보면 먼저 방문하고 visited[2]를 True로 만듭니다. 그다음으로 adj[2]를 가져오는데 그림을 보면 adj[2]={1, 3}입니다. 이 중 한 방향을 선택하게 되는데, 여기서는 정점 1을 선택했다고 합시다.

위의 그림을 보면 정점 1을 인수로 __dfs_recursion() 메서드를 호출했습니다. 정점 1을 방문하고 visited[1]=True로 합니다. adj[1]={0, 2}입니다. 정점 2는 이미 방문한 상태이므로 정점 0을 인수로 다시 __dfs_recursion을 호출합니다.

위의 그림을 보면 현재 정점은 0입니다. 먼저 방문 이후 visited[0] = True로 합니다. adj[0]은 {1}입니다. 정점 1은 이미 방문한 상태입니다. 현재 정점 0에서 더 이상 갈 수 있는 곳이 없습니다. 그렇다면 정점 0으로 오기 전 정점으로 돌아가야 합니다. 현재 스택 프레임의 바로 밑에 매개변수 1을 가진 스택 프레임이 있지요. 그 스택 프레임으로 돌아간다는 것은 현재 정점 0에서 정점 1로 돌아간다는 것입니다. for 문이 끝나는 동안 아직 방문하지 않은 정점을 발견하지 못했다면 __dfs_recursion(0)은 종료됩니다.
함수가 종료되면 스택 프레임도 사라집니다. 그래서 바로 아래의 스택 프레임인 정점 1로 돌아올 수 있는 것입니다. 정점이 1인 상태에서도 adj[1] = {0, 2} 모두 방문한 상태이므로 for 문이 끝나면서 함수가 종료되고, 정점 2로 돌아올 수 있습니다.
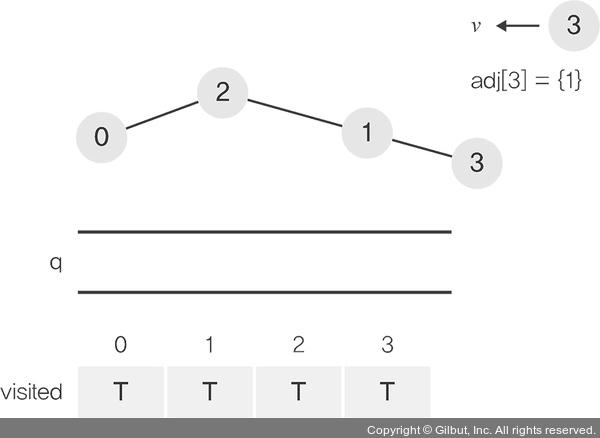
정점이 다시 시작 정점인 2로 돌아왔습니다. adj[2]={1, 3}에서 정점 1 방향으로 끝까지 따라갔다가 온 셈입니다. 이제 남은 방향으로 쭉 따라가야 합니다. 인수를 정점 3으로 하여 다시 __dfs_recursion 메서드를 호출합니다.
방문을 하고 visited[3]=True로 만들어 adj[3]={2}를 얻어 옵니다. 그런데 정점 2는 이미 방문한 상태입니다. 그렇다면 for 문이 종료되면서 함수도 종료되어 스택 프레임도 사라집니다. visited를 보면 모든 노드를 방문했다는 것을 알 수 있습니다. 그렇다면 이 시점에서 알고리즘을 끝내도 됩니다만 그렇게 하지 않습니다. 반드시 시작 정점으로 돌아가 시작 정점에서 더 이상 따라갈 정점이 없을 때 알고리즘을 종료합니다.
스택 기반의 DFS를 스택 프레임이 아니라 스택 자료구조와 반복문을 가지고 구현할 수도 있습니다.
# graph_traversal.py def iter_dfs(self, v): """ 시작 정점으로 돌아가 더 이상 방문할 정점이 없어야 종료 """ s=Stack() self.init_visited() s.push(v) #방문 체크 및 방문 self.visited[v]=True print(v, end=" ") #아직 방문하지 않은 정점을 방문했는가 is_visited=False while not s.empty(): is_visited=False v=s.peek() # 인접 리스트를 받아온다. adj_v = self.adj_list[v] for u in adj_v: if not self.visited[u]: s.push(u) # 방문 체크 및 방문 self.visited[u]=True print(u, end=" ") # 아직 방문하지 않은 정점을 방문했으므로 is_visited=True break if not is_visited: s.pop()위의 코드는 먼저 while 문 내에서 dfs처럼 큐에서 정점을 바로 가져오지 않고 peek() 메서드로 읽어만 옵니다. 그럼 아직 현재 정점이 스택에 남게 됩니다.
그 후 현재 정점 v에 대해 adj[v]를 구해 와 for 문을 돌며 방문하지 않은 정점에 대해 방문과 방문 체크를 합니다. 이때 방문하지 않은 정점을 만나 방문을 한다면 is_visited 변수를 True로 만듭니다. 방문하지 않은 정점을 발견하면 현재 정점이 방문하지 않은 정점으로 이동하므로 for 문을 빠져나가 다시 while 문의 처음부터 실행하면 됩니다.
이때 for 문을 빠져나올 때 두 가지 경우가 있습니다. 먼저 is_visited가 True면 이는 방문하지 않은 정점을 발견하여 이동한 경우입니다. 이때는 스택에 이전 정점 위에 이번에 이동한 정점이 쌓이게 됩니다. 이렇게 해야 다음에 모든 정점을 방문한 시점에서 pop()으로 현재 정점을 제거하고 이전 정점으로 이동할 수 있습니다. is_visited가 False라면 이는 adj[v]의 모든 노드를 방문한 상태를 의미합니다. 이때는 이전 정점으로 이동해야 하므로 스택에서 현재 정점을 pop해야 합니다. 그럼 이전 정점으로 돌아갈 수 있습니다.
두 번째로 그래프가 연결되어 있지 않고 여러 개의 연결 요소로 나뉘어 있다면 어떨까요? 그렇다면 지금의 dfs로는 모든 정점을 방문하지 못하고 시작 정점에 연결된 요소의 정점들만 방문하게 됩니다. 이를 해결하는 메서드를 만들어 보겠습니다.
# graph_traversal.py def dfs_all(self): self.init_visited() for i in range(len(self.visited)): if not self.visited[i]: self.__dfs_recursion(i)위의 코드를 이용하면 연결된 그래프가 아니여도 모든 정점을 순회할 수 있습니다.
Tip) bfs와 dfs는 어디에 사용되는가?
너비 우선 탐색과 깊이 우선 탐색 모두 그래프의 모든 정점을 순회하는 방법입니다. 이 두 가지 방법은 그래프나 트리 알고리즘에서 쉽게 찾아볼 수 있습니다. 대표적으로 뒤에서 공부할 프림 알고리즘과 데이크스트라 알고리즘은 BFS를 응용한 버전이라고 할 수 있습니다.
'Algorithm' 카테고리의 다른 글
자료구조 핵심 원리 - 트리 (0) 2022.09.28 자료구조 핵심 원리 - 스택과 큐 (0) 2022.09.23 자료구조 핵심 원리 - 연결 리스트 (1) 2022.09.23 자료구조 핵심 원리 - 동적 배열 (1) 2022.09.23 자료구조 핵심 원리 - 재귀 함수 (0) 2022.09.22