-
알고리즘 - 보이어/무어법 (문자열 검색)Algorithm 2022. 2. 10. 16:40
Boyer-Moor method는 이론이나 실제 효율에서 KMP법보다 뛰어나서 실제 문자열 검색에서 널리 사용하는 알고리즘이다.
패턴의 끝문자에서 시작하여 앞쪽을 향해 검사를 수행한다. 이 과정에서 일치하지 않는 문자를 발견하면 미리 준비한 표를 바탕으로 패턴이 이동하는 값을 결정한다.
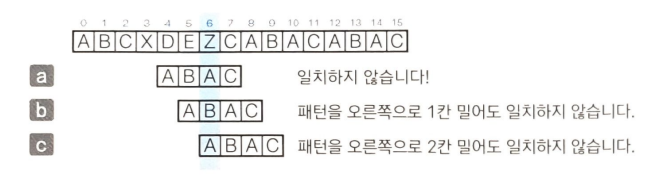
예를 들어 'ABCXDEZCABACABAC'에서 패턴 'ABAC'를 검색하는 과정을 살펴보자.

위 그림의 a처럼 텍스트와 패턴의 첫 문자를 나란히 놓고 패턴의 마지막 문자 C에 주목한다. 같은 위치에 있는 텍스트의 X는 패턴 안에 포함되어 있지 않다. 따라서 b~d 처럼 패턴을 이동해도 텍스트와 패턴은 일치하지 않는다. 이처럼 패턴에 포함되지 않는 문자를 텍스트에서 발견하면 그 위치까지는 건너뛸 수 있다. 그로므로 b~d의 과정을 생략하고 패턴을 한번에 4칸 밀어서 비교한다.

여기서 패턴의 마지막 문자 C를 비교하면 일치하므로 1칸 앞의 문자 A와 텍스트를 비교한다. 패턴의 A와 텍스트의 Z는 일치하지 않기 때문에 패턴을 한번에 3칸 민다.


맨 끝부터 문자를 차례로 비교하여 일치할 때까지 위의 과정을 반복한다. 만약 텍스트의 끝까지 가도록 일치하지 않는다면 텍스트엔 패턴이 없다고 판단한다.
보이어/무어법 알고리즘도 각각의 문자를 만났을 때 패턴을 이동할 크기를 저장하는 표(건너뛰기 표)를 미리 만들어 둘 필요가 있다. 패턴 문자열의 길이가 n일 때 이동할 크기(이동량)는 다음과 같이 결정한다.
- 패턴에 포함되지 않는 문자를 만난 경우
: 패턴 이동량이 곧 n이다.
- 패턴에 포함되는 문자를 만난 경우
: 마지막에 나오는 위치의 인덱스가 k이면 이동량은 n - k - 1이다. 만약 같은 문자가 패턴 안에 중복해서 존재하지 않으면 패턴의 맨 끝 문자의 이동량은 n이다. ex) 'abac'의 'c'를 만나면 이동할 필요가 없으므로 이동량은 n이다.<code>
더보기def bm_match(txt, pat): skip = [None] * 256 # 건너뛰기 표 # 건너뛰기 표 만들기 for pt in range(256): skip[pt] = len(pat) for pt in range(len(pat)): skip[ord(pat[pt])] = len(pat) - pt - 1 # 검색하기 while pt < len(txt): pp = len(pat) - 1 while txt[pt] == pat[pp]: if pp == 0: return pt pt -= 1 pp -= 1 pt += skip[ord(txt[pt])] if skip[ord(txt[pt])] > len(pat) - pp \ else len(pat) - pp return -1
문자열 검색 알고리즘의 시간 복잡도
- 브루트 포스: 시간 복잡도는 O(mn)이지만 일부러 꾸며 낸 패턴이 아니라면 O(n)이 된다고 알려져 있다. 단순하고 비효율적이지만 간단한 경우 빠르게 동작한다.
- KMP: 최악의 경우에도 O(n)이다. 다만 처리하기 복잡하고 패턴 안에 반복이 없으면 효율이 좋지 않다. 그러나 검색 과정에서 주목하는 곳을 앞으로 되돌릴 필요가 없으므로 파일을 차례로 읽어 들이면서 검색할 때 사용하면 좋다.
- 보이어/무어: 최악의 경우 O(n), 평균 O(n / m)이다. 배열을 1개가 아닌 2개로 알고리즘을 구현한다면 효율성이 떨어진다.
일반적으로 파이썬에서 문자열을 검색한다면 표준 라이브러리를 사용하는 것이 좋다.
'Algorithm' 카테고리의 다른 글
자료구조 - 트리 (0) 2022.02.14 자료구조 - 연결 리스트 (0) 2022.02.11 알고리즘 - KMP법 (문자열 검색) (0) 2022.02.09 알고리즘 - 브푸트 포스법 (문자열 검색) (0) 2022.02.09 도수 정렬 (0) 2022.02.08